Audio A/B by type — same prompt, same seed, RTX 5090
Each pair is the identical seeded generation; only the attention kernel differs. ▶ play both and listen. Generated 2026-06-17.
Speed: SageAttention held ~12% faster across all five types (~50s → ~43s warm).
Audio verdict: PRESERVED on single-voice speech, action SFX, and ambient
(spectra match 0.97–0.99, loudness within 0.3 dB). Dialogue shifts (+3.6 dB, multi-voice content diverges).
Music is a high-variance regime — here the current pipeline came out near-silent at this seed, so treat that row as inconclusive, not a sage regression.
Talking head — single voice
PRESERVED
One person speaking a scripted line to camera (speech + lip-sync).
A — current (no acceleration)
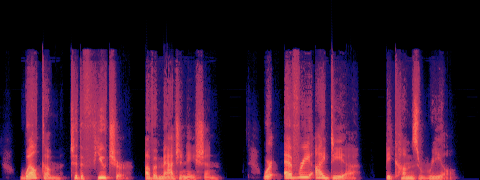
B — SageAttention
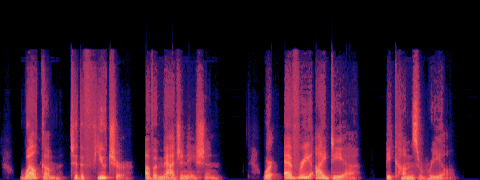
spectral match (mel-cosine): 0.976
· timbre dist (MFCC): 15.0
· loudness B/A: 1.004×
Dialogue — two voices
ALTERED
Back-and-forth man/woman conversation with cafe ambience.
A — current (no acceleration)
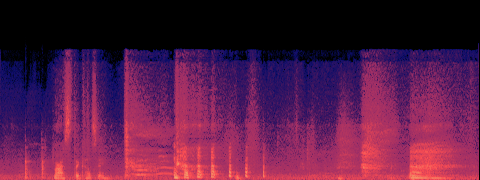
B — SageAttention
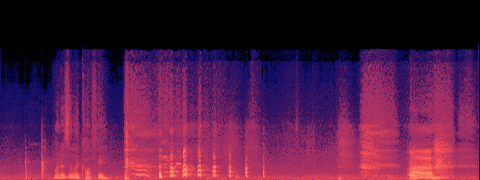
spectral match (mel-cosine): 0.774
· timbre dist (MFCC): 30.1
· loudness B/A: 1.514×
Action — SFX
PRESERVED
Car chase: engine, tyre screech, rain. No voices.
A — current (no acceleration)
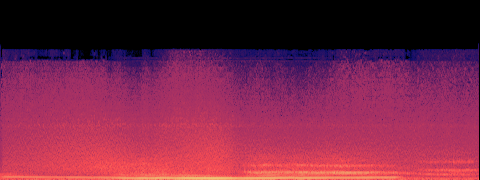
B — SageAttention
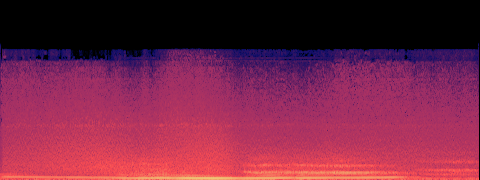
spectral match (mel-cosine): 0.994
· timbre dist (MFCC): 6.8
· loudness B/A: 1.038×
Music
DIVERGENT
Fingerpicked acoustic guitar with street ambience.
A — current (no acceleration)
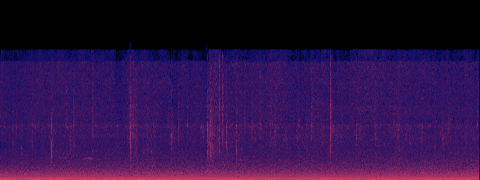
B — SageAttention
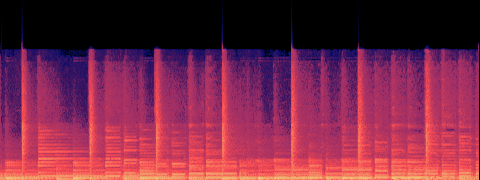
spectral match (mel-cosine): 0.313
· timbre dist (MFCC): 322.4
· loudness B/A: 107.381×
Ambient — soundscape
PRESERVED
Forest waterfall, birdsong, breeze. No voices.
A — current (no acceleration)
B — SageAttention
spectral match (mel-cosine): 0.994
· timbre dist (MFCC): 4.9
· loudness B/A: 0.97×